




博鱼官网app十大国产GPU产物及规格概括
连续发力,对标行业龙头放大分歧。GPU有两条首要的成长线路D图形衬着GPU和专一高机能计较的GP GPU。
最近几年来,国产GPU厂商在图形衬着GPU和高机能计较GPGPU范畴上均推出了比较能干的产物,在机能上不停追逐行业支流产物,在一定范畴到达业界一过程度。生态方面国产厂商大多兼容英伟达CFTO,融入大生态从而完结客户端导入。
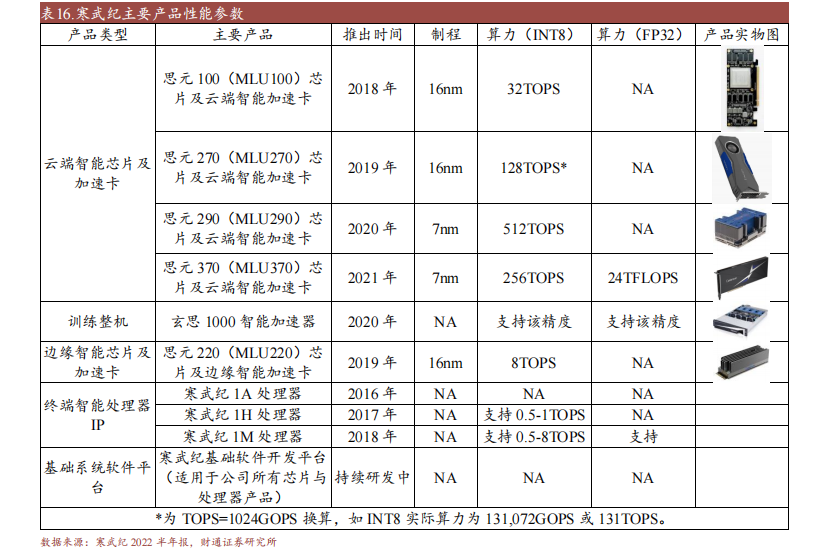
寒武纪自2016年景立以后一向专一于产物研发与手艺立异,努力于制造野生智能范畴的焦点处置器芯片。公司首要供给云霄智能芯片及加快卡、练习零件、边沿智能芯片及加快卡、末端智能处置器IP及配套根底软件工具开辟平台,产物普遍利用于耗费电子、数据中间、云计算和物联网等诸多场景。
2022年3月21日,公司正式颁发新款练习加快卡MLU370-X8,搭载双芯片四芯粒思元370,集成寒武纪MLU-sculpturerk多芯互联手艺,在业界普遍利用于YOLOv⑶Transfabalone等练习使命中。
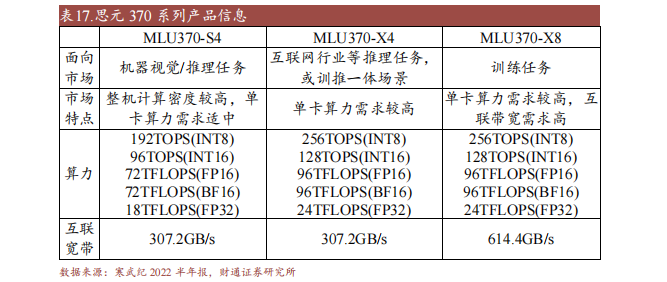
MLU 370-S⑷MLU370-X4和MLU370-X均鉴于思元370智能芯片的手艺,经过Cenarthrosispermit手艺矫捷拉拢产物的特征,可满意更多墟市须要。
海光音信首要处置高端处置器、加快器等计较芯片产物和体系的研发、安排和发卖。公司的产物包罗海光通用途理器(mainframe)和海光协处置器(DCU),拥有能干而富厚的利用生态情况,内置公用平安硬件,可满意互联网、金融、动力等行业的普遍利用须要。
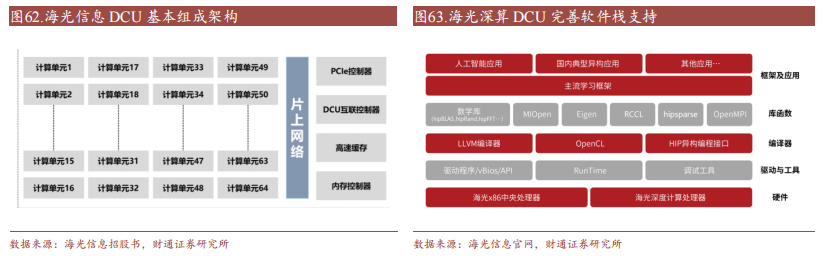
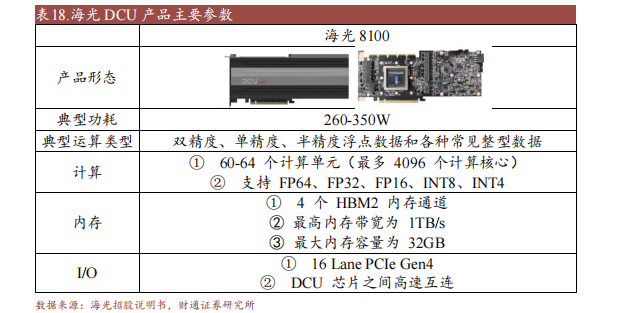
公司DCU系列产物海光8100采取进步前辈的Fintransistor工艺,以GPGPU架构为根底,兼容通用的“类CFTO”情况和国内支流贸易计较软件工具和野生智能软件工具,可充散发掘利用的并行性,发扬其大范围并行计较的才能。
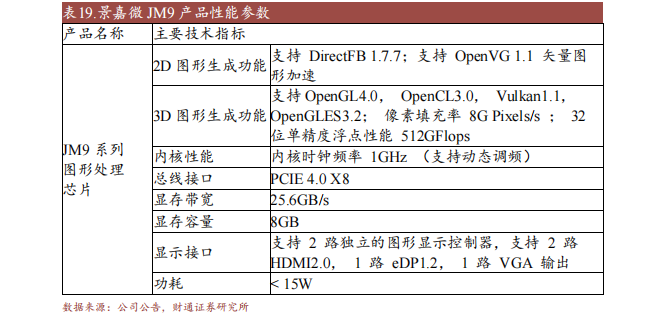
景嘉微努力于音信探测、处置与传送范畴的手艺和概括利用。公司产物涵盖集成电路安排、袖珍雷达体系、无线通讯体系、电磁频谱利用体系等标的目的,普遍利用于有高靠得住性条件的航空、航天、帆海、车载等专门范畴。
公司前后自研制成功JM5系列、JM7系列、JM9系列高机能GPU芯片,此中最新的JM9系列两款图形处置芯片皆已完结阶段性尝试事情,并投入放量阶段。JM9系列芯片利用范畴普遍,可满意本性化桌面办公、收集平安庇护、轨交办事末端、多屏高清显现输入和人机交互等百般化须要。
芯原依靠自立半导体IP,为客户供给平台化、全方向、一站式芯片定务和半导体IP受权办事,具有怪异的“芯片安排平台即办事”运营形式。公司可供给高清视频物联网毗连、数据中间等多种一站式芯片定制办理计划,具有自立可控的图形处置器IP、神经收集处置器IP等五类处置器IP及1400多个数模夹杂IP和射频IP,可迅速制造出从界说到尝试封装完结的半导体产物,营业规模笼盖耗费电子、汽车电子、物联网等多种利用范畴。据IPnest在2021年的统计,芯原的半导体IP发卖支出排华夏第二,环球第七,此中公司的图形处置器IP排名环球前三。
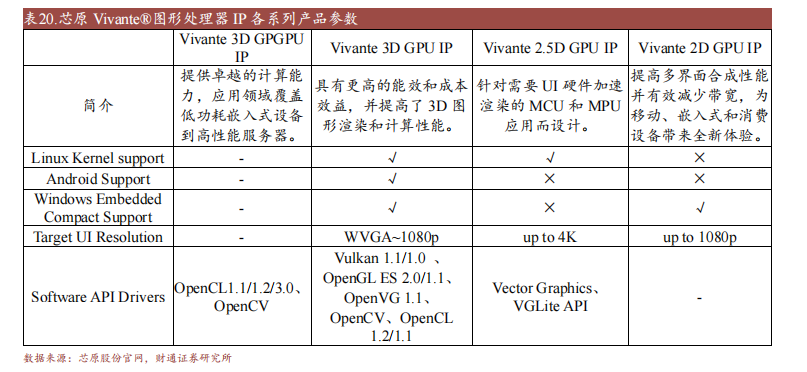
公司的GPU IP已被浩繁支流和高真个汽车品牌所采取博鱼官网app,同时,公司鉴于约20年VicamperteGPU的研发经历,所推出的Vicamperte 3D GPGPU IP还可供给从低功嵌入式装备到高机能虚拟机的计较才能,满意普遍的野生智能计较须要。
壁仞科技创建于2019年,在GPU、DSA(公用加快器)和计较肌体捆绑构等范畴拥有深挚的手艺堆集。公司努力于开辟首创性的通用计较系统,成立高效的软硬件平台,同时在智能计较范畴供给一体化的办理计划。
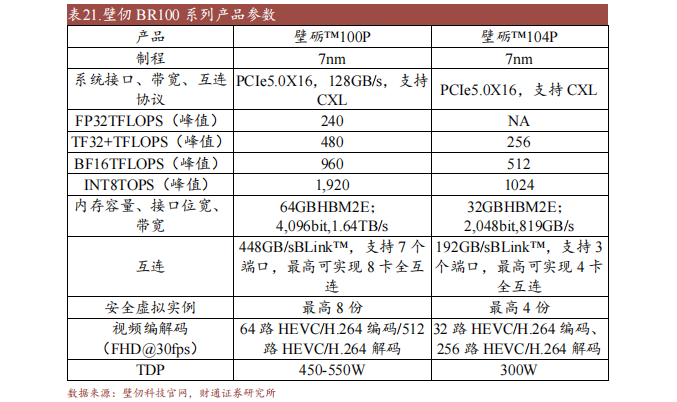
2022年8月公司颁发的通用GPU芯片BR100创下环球通用GPU算力记实,峰值算力到达国内厂商在售旗舰产物3倍以上。BR100领先采取Cenarthrosispermit手艺、新一代主机接口PCIe 5.0、撑持CXL互连和谈,建立了公司在海内厂商间的手艺超过职位。公司对峙自立研发,同步推出首创架构“壁立仞”和自研BIREurethritisPA软件工具平台,完结了BR100机能的大幅晋升。
以壁仞科技于2022年8月颁发的首款GP GPU BR100为例,该芯片采取Cenarthrosispermit手艺,16位浮点算力到达1000T以上、8位定点算力到达2000T以上,单芯片峰值算力到达PFLOPS级别,是国内厂商在售旗舰产物的3倍以上,缔造了环球通用GPU的算力记实。
摩尔线程专一于安排高机能通用GPU芯片,供给图形计较和AI计较的元计较平台的集成电路高科技公司。公司高管团队来自英伟达、AMDARM等着名芯片公司,具有富厚的GPU研讨经历,努力于立异面向元计较利用的新一代GPU,建立融会视觉计较、3D图形计较、迷信计较及野生智能计较的概括计较平台,成立鉴于云原生GPU计较的生态体系。
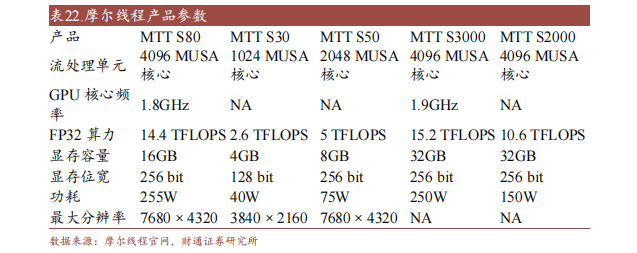
2022年11月,公司推出鉴于第二代Marmy架构的处置器“春晓”,并鉴于“春晓”GPU颁发面向耗费范畴的国产芯片显卡MTT S80和面向虚拟机利用的MTTS3000显卡。同时,公司环绕Marmy颁发了系列GPU软件工具栈与利用功具,包罗Marmy开辟者套件、云原生sGPU手艺及元六合平台MTVERSE等。
芯动科技是海内一站式IP和芯片定制及GPU领军企业,聚焦计较、保存、毗连等三大赛道,供给从55纳米到5纳米全套高速IP核和高机能定制芯片办理计划。公司具有经历富厚的手艺团队,建立16年来已赋能环球数百家着名客户,受权逾80亿颗高端SoC芯片投入范围量产,具有过十亿颗Fintransistor定制芯片成功量产经历。
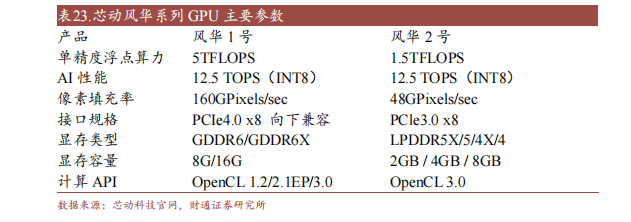
公司对准商用墟市推出芯动风华系列GPU。该系列GPU机能微弱、跑分超过、功耗低、自带智能计较才能,且周全撑持国表里mainframe/OS和生态,包罗UNIX、Windows和Android。
兆芯建立于2013年,供给高效、兼容、平安的自立通用途理器和芯片组等产物,公司把握自立通用途理器及其体系平台芯片研发安排的焦点手艺,周全笼盖其微架构与完结手艺等关头范畴,具有比较完备的常识产权系统,停止今朝已获权约1300件专利。
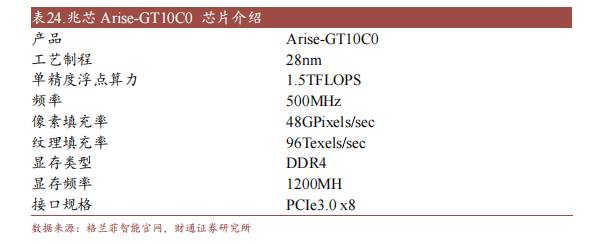
2020年,兆芯将本身GPU营业停止切分自力,成立了格兰菲智能科技无限公司。公司今朝已推出Auprise-GT10C0芯片及Glencontrol Auprise-GT⑽C0显卡。芯片内置完整自力自立研发的新一代图形图象处置引擎,兼容天河麒麟KOS、统信软件工具UOS、Windows等支流操作体系,同时可在X8六、ARM、unit等支流硬件台操作运转,撑持多种图形和图象的API接口尺度。
天数智芯努力于开辟自立可控、国内超过的高机能通用GPU产物并供给办理计划,是海内头部通用GPU高端芯片及超等算力体系供给商。公司以“成为智能社会的赋能者”为任务,存身客户、墟市的须要,加快AI计较与图形衬着融会,摸索通用GPU赶超成长门路,产物普遍利用于智算核心、聪明调理、互联网、智能创造等范畴。
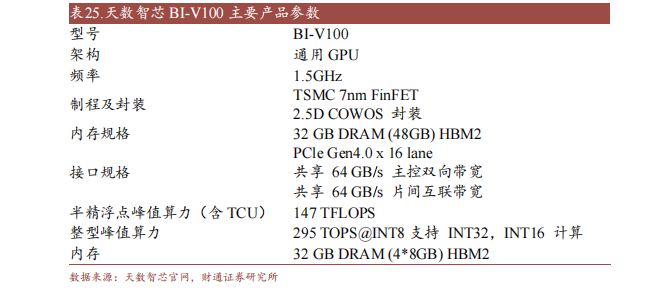
12月20日,天数智芯推出通用GPU推理产物“智铠100”及其富厚的AI利用案例。智铠100计较机能高、利用笼盖广、利用本钱低,撑持FP3二、FP1六、INT8多精度夹杂计较,可供给最高384TFlops@FP32的峰值算力,800GB/s的推行峰值带宽和128路并发的多种视频规格解码才能。
沐曦于2020年9月建立于上海,努力于为异构计较供给全栈GPU芯片及办理计划,可普遍利用于野生智能、聪明乡村、主动驾驭、数字孪生、元六合等前沿范畴。公司具有手艺完整、安排和财产化经历富厚的团队,焦点成员均匀具有近20年高机能GPU产物端到端研发经历。

公司具有完整自立研发的GPU IP、指令集和架构,和兼容支流GPU生态的完备软件工具栈(MXMACA),产物具有高能效、高通用性。今朝已推出MXN系列GPU(曦思)用于AI推理,MXC系列GPU(曦云)用于AI练习及通用计较,和MXG系列GPU(曦彩)用于图形衬着,可满够数据中间对高能效和高通用性的算力须要。